Content modeling Introduction
Audience: Archivists, system administrators
Terms showing in bold are referenced in the glossary.
This document is a general-purpose introduction to content modeling concepts in Pocket Archive. For detailed technical information on how to set up a content model for a Pocket Archive instance, see the content modeling manual
Content model and types
Content modeling refers to the configuration of an information system, such as Pocket Archive, with the goal of instructing the system how it should understand and handle user-supplied contents.
The term "content model" has various meanings in the libraries and archives world. In the context of Pocket Archive, a content model is the complete set of definitions of content types, their properties, and the relationships between them, sometimes also called an ontology. There is one and only one content model for each installation of Pocket Archive.
In addition to defining semantic structures, the Pocket Archive content model defines operational behaviors, for example how to generate presentation derivatives for certain content types.
A content type is a single content category in a content model. Each resource must be assigned one and only one primary content type.
A schema is a machine-readable document, made up of configuration files that describe all the semantic and behavioral aspects of a content type.
Type inheritance
Content types are hierarchical, starting with a single common archtype, called "Anything", which is refined into broad categories, and further into more specific categories.
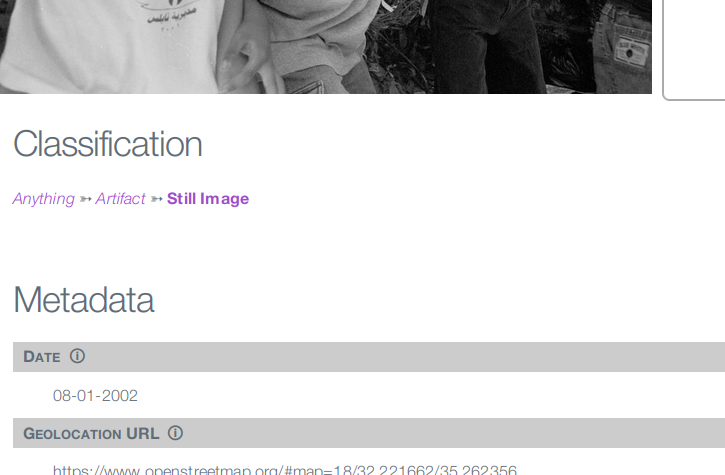
This hierarchy is visible in the presentation page of a resource, e.g. an Artifact of type "Still Image". The page has a "Classification" section with a chain of links, such as: "Anything ➳ Artifact ➳ Still Image". This means that the resource being viewed has a "Still Image" primary type (the most specific type), which is a specialization of "Artifact", which is in its turn a specialization of "Anything". Searching for all Still Images will find this resource. Also searching for Artifacts, or for Anything, will find this resource. [WIP note: the links in the classification are not yet working. Eventually they will resolve to listings of all resources in a given content type.]
In other words, each content type inherits common properties from a broader type and may add more properties specific only to that type.
For example, we define a Postcard type as a sub-type of Artifact. Artifact has
some properties such as author, location, date, etc. It also has an has file
relationship that allows the artifact to be related to any files. The Postcard
type will inherit all these properties automatically and there is no need to
redefine them.
We can add more properties to the Postcard type, e.g. an inscription property
that contains text inscribed on the object. We can also add has_recto and
has_verso relationships with Bricks representing the two faces of the
postcard. Finally, we can re-define the has_file property to restrict the
relationship to a sub-tye of File, e.g. StillImage. All these properties
are only available to the Postcard type and its sub-types (if any are defined).
If we later decide that all artifacts need a new property, e.g. description,
we can add that to the Artifact type, and the Postcard type and all other sub-
types of Artifact will automatically inherit it.
This method allows to create both simple and complex hierarchies of content types, and keep them manageable.
Foundational types
Pocket Archive supports the customization of the content model for each of its running instances, even for multiple instances running on the same machine from the same code base, if they point to different configurations. Some schemata that make up the foundations of the Pocket Archive content model, are already provided and unchangeable. Pocket Archive relies on these schemata for some of its basic functionality.
The fundamental type is Anything. As the name suggests, all resources in the
system ultimately belong to this type. Anything sets some basic properties
that cannot be redefined, such as id or source_path, and others that are
added for convenience and may be redefined in sub-types.
Anything has three immediate child types: Artifact, File, and Brick.
These types may be used as primary types for resources, but more likely, their
child types may be used.
Artifact is a digital surrogate of a physical and/or intellectual object, such as a photograph, a video, a letter, a painting, etc. This resource contains data related to the subject, content, author, taxonomy, etc. of the intellectual work.
File is a digital capture or document related to an artifact. The file is accompanied by a metadata resource, which is automatically generated fom the metadata that the archivist enters in the laundry list. These metadata should be exclusively about the file itself, e.g. time of creation, file size, file type, etc, as well as how the file relates to the artifact (e.g. detail shot, documentation, transcript, 3/4 view, etc) or other files. Some of these metadata are generated automatically by analyzing the file during the submission process. Information about the artifact itself goes exclusively into the artifact resource.
Brick is a structural element used to build logical structures with multiple resources. Bricks can represent many things: the ordering of chapters and pages in a book, front and back sides of a postcard or a vinyl record, the ordering of artifacts and collections in a collection, etc. They may have any kind of metadata, and/or they may reference an artifact or file, that they "stand in" for. They are mostly automatically generated by the submission process, and are mostly hidden in the presentation, but they can be explicitly created in a laundry list to create specific structures.
Bricks as structural tools
The use of bricks for ordering purposes is worth spending some extra words. While some objects may look naturally ordered, such as the pages in a book, other abstract entities, such as collections, may be created from resources in other collections. The resources in the collection cannot have an ordering number of their own if they are owned by multiple collections, and for this reason, bricks are used to provide ordered stand-ins.
Bricks can be used for this purpose in a variety of ways. A very simple use case is illustrated below:
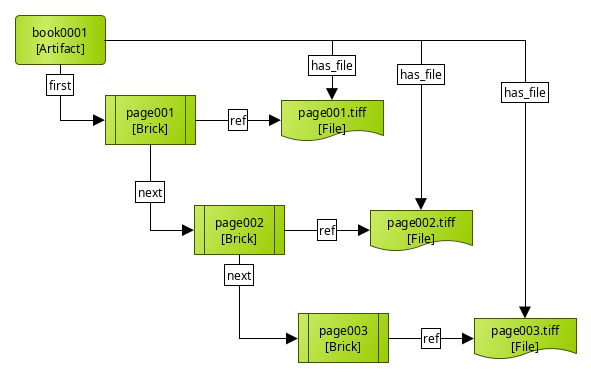
In this example, a book resource (an Artifact) contains some ordered pages
represented by Files. Note that there is a direct relationship between the
artifact and its files, because the files are directly related to the content
of the book. There are also indirect relationships going from the book to the
page structural elements (Bricks), which provide an ordering (via first and
next properties) and reference (ref) the files which they represent.
This example is contrived, as we could have just as easily pointed the first
relationship from the book to the first file, and the next one from one
file to the next. But, what if we have multiple files per page:
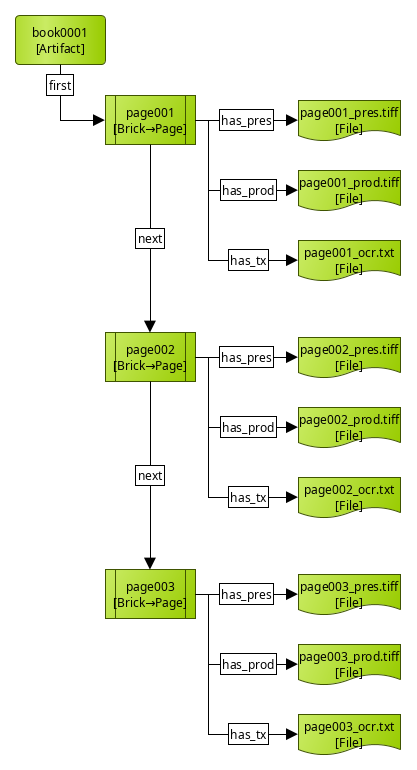
In this case, closer to a real archival scenario, we have an archival
master file, a production master file, and a transcript text file for
each page of the book. A single-file ordering wouldn't work here, so, a
sub-type of Brick is used to represent a page. Each Page resource can contain
metadata about its content and position in the book, and groups all the files
related to a page, each with a specific relationship (has_pres, has_prod,
has_tx) so that they can be clearly tracked.
A more complex example, less common because it is more laborious to set up, but entirely possible, involves an Artifact resource that has multiple structures, such a full book and its excerpt:
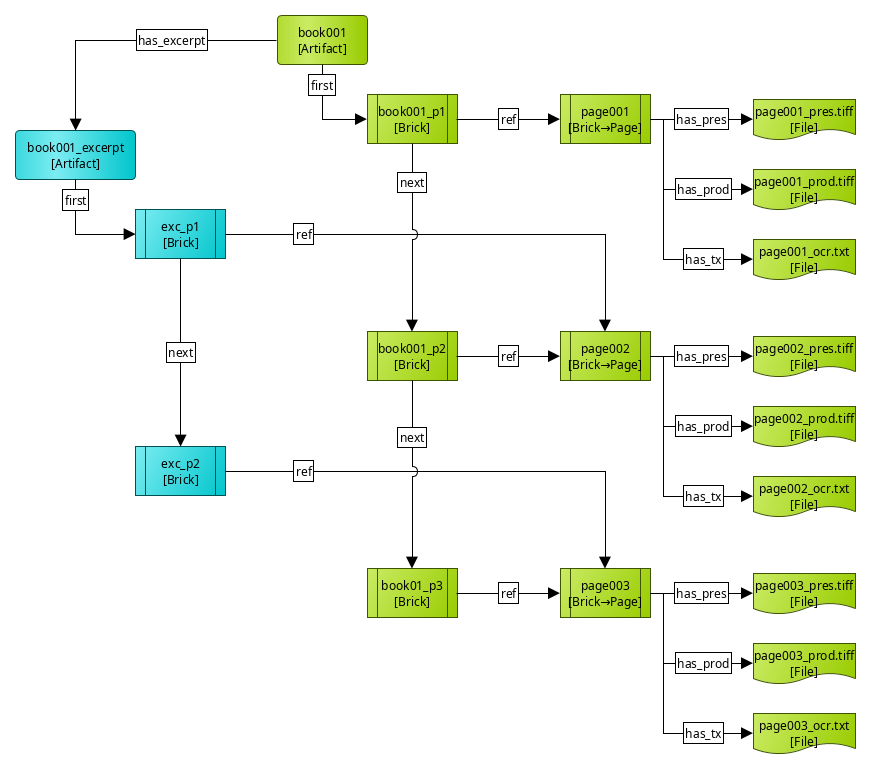
In this case, in addition to the Page resources of the previous example, we have an additional layer of bricks only to keep ordering. The pages keep their role as representatives of the content of the pages and groupings of related files, but they have no ordering information. This is delegated to two sets of bricks, one defining the ordering for the full book (pages 1÷3), the other for the excerpt (pages 2÷3, which in the excerpt are numbered 1 and 2).
This use case is seldom used for books, especially in large collections where
setting up multiple orderings for individual artifacts is not practical, but it
may be very useful in building collections by "borrowing" already submitted
resources that belong to another collection. The coll2 row in the example
laundry
list
does exactly that within a couple of lines. Pocket Archive takes care of
creating the appropriate bricks.
Assigning content types
Each resource is assigned one and only one content type. This is done by
setting the content_type property to one of the available type codenames.
There is no need to define a specific content type for every object in the archive. Only if enough resources sharing similar characteristics start populating the archive, and there is a need to set them apart from other rsources, a new type may be created.
If one-off items are acquired, it is mostly fine to classify as the most fitting type at hand. For example, if a Book and a Manuscript types are defined that inherit from Artifact -> Text, and one has a flyer to catalog, one can assign Text as the type because a flyer does not fit within either of the more specific types. This should be done in exceptional cases: assigning a very broad type to a resource results in loss of information and specificity, and if done habitually, it makes for a poorly usable archive.
While content types can be added, removed, and updated at any time, some times this implies updating all the resources that belong to those types, which can be laborious. The initial type hierarchy should be carefully evaluated before starting to populate the archive in order to minimize such labor.
Properties
Properties are bits of data attached to an individual resource. They can be descriptive, such as "label", "description", "author"; structural, such as "has parent", "has relationship", "has next sibling"; technical, such as "file size", "MIME type", "checksum"; etc.
The content model defines which properties can be assigned to which content type. It can also define how many values a property can have, which data type it should be (string, number, date, relationship, etc.), and other aspects. Not all of these details are always defined for all properties; in fact, many properties are usually not too strictly defined. This is a primarily curatorial decision that should be made while setting up the system, and further refined with usage over time.
Setting properties
Only properties that are defined in the resource schema can be added to a resource. Tools [WIP note: not yet implemented] shall be made available to write out the complete schema of a given instance of Pocket Archive to a file, that can be used as a reference.
The only system-mandated properties for all resources are content_type and,
for files, source_path. content_type determines the schema to be
applied to the resources, and the rules applicable to all other properties.
Property names and codes
Properties have a few names and identifiers:
- A codename, which is normally made of lowercase letters, numbers, and
underscores, e.g.,
file_size. This is an identifier used by archivists in the laundry list header. It must be unique for each property. - A human readable description, which is what shows in the presentation when resource properties are listed. This should be a concise label starting with a capital letter, e.g., "File size".
- A URI, which is mostly hidden from archivists and end users, but is a fundamental Linked Data building block ensuring that the property is globally unique. Most users need not be concerned with the URI for ordinary operations.
Property constraints
Properties can be wide open, i.e. they accept any (or no) values, or they can
be more or less strictly constrained. The advantage of constraining properties
is that increases relevance and accuracy of search results: for example, by
defining image_height as a number rather than a generic string, it is
possible to find all images with a height of less than 1000 pixels. Also,
constraining the allowed values to a controlled vocabulary may prevent
confusion. For example, if the is_published property is meant to be a
true/false value, by constraining the range of values to true and false we
can avoid having yes, Yes, YES, y, Y, 1, t, TRUE, published,
etc., entered instead of the intended value (YES, it does happen).
On the other hand, a too constrained property can make cataloging and archiving difficult, especially if a one-off case comes up that doesn't fit some imposed constraints. Which properties get constrained and how is a curatorial decision.
Below are brief descriptions of the different types of constraints supported by Pocket Archive. This information is mainly useful to archivists. When a submission undergoes validation (explained further below), errors may show that require adjusting the metadata according to the defined constraints. Understanding the constraints may help fixing the errors. Details on how to define these constraints are in the Content modeling manual.
Type
This constraint defines what kind of data may be entered for a property. It can be a string (pretty much any text is fine); a number; a date or date and time; a relationship; or a URL. More types may be added at later stages of Pocket Archive development.
The URL type is regarded as a string for constraint purposes, but it is treated especially in the presentation, where it will show as a hyperlink. The archivist is responsible for ensuring that the hyperlink points to a valid location. A good archival practice is to point to a Wayback Machine URL if available, which allows the archivist to display the page "frozen" at the time of the submission, before it might be altered or taken down altogether.
The property type also results in a hyperlink, but it is used only for
resources managed by the archive. In a laundry list, a resource ID is used, or
lacking that, the source_path of the related resource (which will be replaced
by the submission process with a generated ID). Once validated and archived,
Pocket Archive guarantees that the relationship remains sound. System-defined
properties such as has_member, has_preferred_representation, etc. are
resource type properties.
Cardinality
Cardinality is the number of values that a property can have on any resource. Minimum and maximum cardinality can be defined to cover a wide range of scenarios: a minimum cardinality of 1, for example, means that at least one value must be provided, which means, that property is mandatory. A maximum cardinality of 1 means that the property is single-valued; etc.
Range
[WIP note: not yet implemented]
The range of a property depends on its data type: for a number or a date, it can be a minimum and/or maximum value range; for a string, a specific pattern can be defined; for a resource type, the content type(s) of the resources pointed to can be restricted.
Validation
Validation is an automatic action performed by the submission process that verifies that all the input data of the SIP are conforming to their schema. If validation passes, the submission process continues as expected; if it fails, the whole submission fails and the process stops. In both cases, a report is generated, so that in case of failure, the depositor can inspect the validation results and adjust the metadata before re-submitting the SIP.
[WIP note: report generation and delivery is not yet implemented.]